
I’ve been running my “T-Comm” Bus Locator website for over seven years now. As a quick recap, on the backend, it’s a procedural PHP/MySQL website, kind of a typical thing one would see of PHP development circa 2000s.
The high level overview is that every minute or two, the system polls TransLink’s real time information APIs for the locations of the all the buses in the system. The system then calculates some information based on TransLink’s GTFS data, which has the schedule information for the entire system. Then it saves the data into a MySQL database, and some other outputs for use on the web interface.
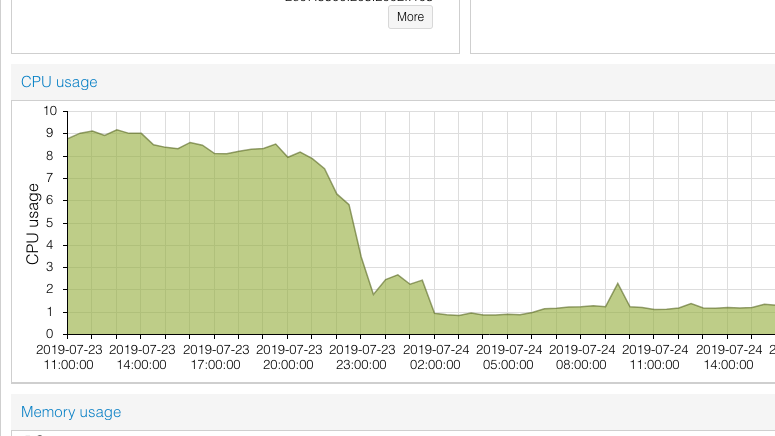
So naturally as more buses operate during the daytime (up to around a thousand buses), the CPU load increases during the day, then drops off at night (down to several on the Night Bus routes). It could take about two minutes to calculate all the necessary information to update all the buses during the daytime
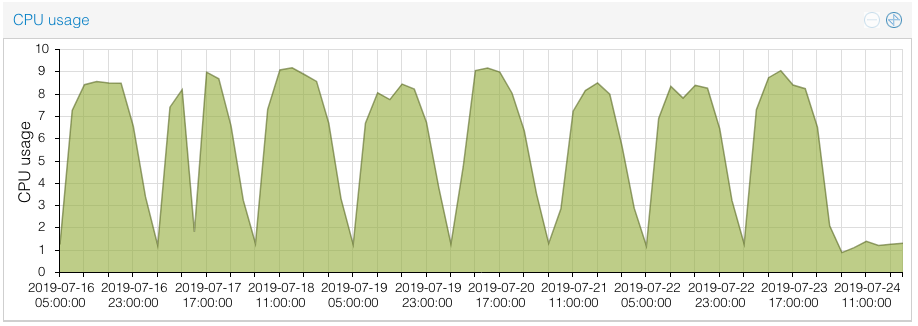
Last night, I set off to find a quick way to optimize this, without having to rewrite the entire system (which arguably it sort of needs, but that’s for another day). From a cursory at the system resources using tools such as htop, it was pretty obvious that the bottleneck was on the MySQL database and its reading and writing to the relatively slow hard disks.
Caching Database Reads with Redis
There was a lot of data from the GTFS schedule information which was being queried for every bus on every location update. This included getting the geographic coordinates of the route the bus was on, the stops along the route, and figuring out when a bus’s day starts and ends.
Since all of those are static data (meaning it doesn’t change—except four times a year) and that the data would likely be needed for as long as the bus is on that route or out that day, these are good candidates to cache in memory so that it doesn’t need to be queried from the database every time.
I chose to install Redis, a service which can store different data structures in memory, and the phpredis module for PHP to interact with Redis. Although Redis supports fancy data types such as lists, hashes, sets, and some cool sounding things like HyperLogLogs, for my purposes though, I only needed the basic “set” and “get” functions.
I’m not going to post any working code samples, because as I mentioned earlier, the code I’m using is quite dated and somewhat embarrassing, but here’s the pseudocode for the idea behind the read cache:
Before – No cache:
result = query_the_database(...)
foreach (result as row) {
// process the row
}After – With Redis cache
cachedResult = getFromRedis(identifier)
if (!cachedResult) {
result = query_the_database(...)
cachedResult = serialize(result)
saveToRedis(identifier, cachedResult)
}
else {
result = deserialize(cachedResult)
}
foreach (result as row) {
// process the row
}Basically, a get operation is done to see whether the data we want is already stored in Redis. If it is, deserialize it into the original data structure. If the data is not there, query it from the database, and serialize it into a string which can be stored in Redis.
Batching SQL Insert/Update Queries
Normally a SQL update query looks like this:
UPDATE table_name SET data_column=new_value WHERE identifying_column=row_identifier;
There isn’t a standard way to update multiple rows with multiple different values. However on MySQL specifically (and derivatives like MariaDB), it’s possible to do an INSERT ... ON DUPLICATE KEY UPDATE which basically is a “create or update” or “upsert” command. This relies on having at least one unique key (primary key works too) included in the query.
INSERT INTO table_name (identifying_column, data_column)
VALUES
(row_identifier, new_value),
(another_row_identifier, another_value)
ON DUPLICATE KEY UPDATE
data_column = VALUES(data_column)
Let’s explain that query:
- Line 1 – Declare the table we want to insert/update, as well as the columns. We assume that the
identifying_columnis a unique index on the table. - Lines 3-4 – These are the new values to insert or update into the table.
- Line 6 – Declare the value to update for each column in case the row already exists based on the unique index. Here the
VALUES()function is used to refer to the value as defined in the insertion on lines 3-4.
This concept only works if it’s not necessary to care about whether the rows are being inserted or updated. If the intention is that rows should only be updated and not created, then this kind of query will not work.
Conclusion
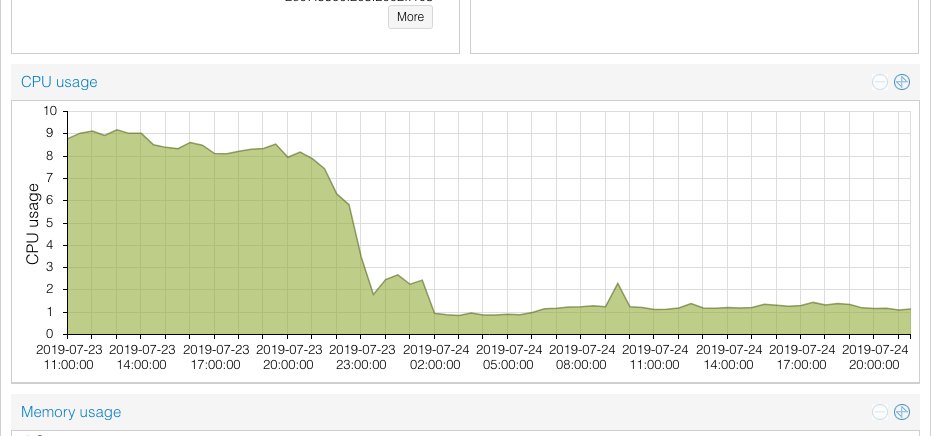
Combining these two optimizations, the time to process the bus location updates dropped from about a minute or two down to a few seconds! CPU usage no longer significantly increases during the daytime. The tradeoff is that Redis uses about 50-150MB more memory throughout the day, but on my server I have quite a bit of free memory so that’s not really a problem for me.
